Сравнение отпечатков документов

Длина подстроки, по которой высчитывается значение функции. Значение должно задавать длину строки, при которой множественное совпадение различных строк длины с другим документом будет считаться подозрительным. Все обнаруженные совпадающие подстроки длиной меньше не будут расценены алгоритмом как плагиат. С учетом генерализации исходного кода, которая сводит анализируемый документ практически… Читать ещё >
Сравнение отпечатков документов (реферат, курсовая, диплом, контрольная)
После отбора всех хэшей документа необходимо сравнить два набора хэшей друг с другом, чтобы определить степень присутствия одинаковых участков в обоих документах.


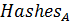
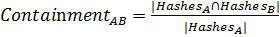
Назовем последовательности хэшей и отпечатками документов и соответственно. Определим значение как степень «присутствия» документа в документе по формуле [31]:

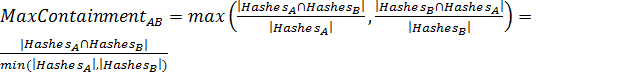
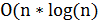
.
Далее можно определить значение максимального «присутствия» между документами и по формуле, которая выводится из предыдущей формулы для расчета :

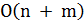
.


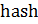
Для расчета данного значения необходимо быстро вычислять значение пересечения двух наборов хэшей. Для этого можно отсортировать оба набора (алгоритмическая сложность), где — количество сортируемых элементов) и затем, используя алгоритм соединения слиянием сортированных списков [32], вычислить повторяющиеся значения хэшей и их количество (алгоритмическая сложность, где и — размеры наборов хэшей).

Для поиска всех значений применяется метод грубой силы (т.е. проводится сравнение каждого документа с каждым). Для ускорения работы алгоритма можно сравнивать не все хэши, а, например, первых хэшей, где — целочисленное значение, которое может меняться в зависимости от степени оптимизации. Однако на практике количество документов и их размер не столь велики, чтобы время работы требовало использования данного подхода, который может влиять на качество поиска плагиата.
Поиск совпавших областей в парах документов
После нахождения всех значений часть значений отсеиваются по определенному числовому порогу, чтобы исключить неверные совпадения, значение которого принадлежит отрезку [0.0, 1.0). Так как заданное на входе алгоритма значение k (длина строки, по которой вычисляется хэш) является длиной подстроки, которая при совпадении с большой долей вероятности является заимствованной из другого документа подстрокой [15], пороговое значение должно быть сравнительно небольшим. В данной программе значение равно, что показывает хорошие результаты в отношении отсеивания неверных совпадений.
После отсеивания всех неверных совпадений начинается поиск совпавших участков среди пар документов.
Необходимо рассмотреть все пары совпавших хэшей среди отпечатков двух документов. Для каждой такой пары находятся положения хэшей в обоих документах, и можно считать, что области, по которым были вычислены данные хэши, совпадают между собой. Затем алгоритм пытается расширить области, осуществляя проверку соседних значений хэшей на границах этих областей в обоих документах. В случае, если пограничные хэши совпадают — область расширяется. Процесс повторяется до тех пор, пока значения хэшей на границах совпадающих областей не станут различаться Позиции совпавших областей запоминаются и записываются в исходных документах.
Описание параметров алгоритма
Как было отмечено ранее, алгоритм поиска и сравнения отпечатков использует два параметра, k и h, которые задаются определенными константными значениями:
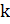
1) — длина подстроки, по которой высчитывается значение функции. Значение должно задавать длину строки, при которой множественное совпадение различных строк длины с другим документом будет считаться подозрительным [15]. Все обнаруженные совпадающие подстроки длиной меньше не будут расценены алгоритмом как плагиат. С учетом генерализации исходного кода, которая сводит анализируемый документ практически до взаимодействия трехсимвольных переменных с математическими операторами и другими конструкциями языка Java, берется значение равное. Это значение больше, чем наиболее длинные генерализированные конструкции, которые зачастую встречается в данном языке.
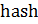
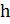
2) — длина «окна» в рамках которого необходимо выбрать хэш, чтобы он вошел в отпечаток документа. Значение варьируется в зависимости от размера документа, но не может быть менее 15 и более 35. Наименьшее значение выбирается в случае, если документ имеет размер менее 8000 символов. Если документ больше, то можно увеличить значение, чтобы уменьшить размер получаемых отпечатков для ускорения работы алгоритма. Оценка верхней границы параметра получена экспериментально. При ее превышении в отпечаток документа не попадает значительная его часть, и плагиат может быть не выявлен.